Anthropic's Claude Opus 4.8 ships faster, cheaper AI model
Serge Bulaev
Anthropic has released Claude Opus 4.8, which may be faster and cheaper than previous versions. Testing suggests it completes tasks about 2.5 times quicker and at about one-third the cost in fast mode. Early results and user feedback indicate better reliability for web tasks and possible improvements in spotting coding errors, though outside audits are still limited. Some benchmarks suggest Opus 4.8 leads in certain coding tasks but might lag behind OpenAI's Codex for command-line work. If more reviews support these findings, Opus 4.8 could be a good choice for developers, but some teams may still prefer other models for specific needs.

The release of Anthropic's Claude Opus 4.8 offers a faster, cheaper AI model, with initial tests showing a 2.5x speed increase and a 3x cost reduction. This latest update enhances the platform's agentic capabilities and safety protocols, positioning it as a powerful new option for developers and enterprise clients.
Speed, cost, and agent capacity
The new model enhances performance by operating up to 2.5 times faster and three times cheaper than previous versions in fast mode. It also introduces dynamic agentic capabilities, allowing the model to manage tens to hundreds of parallel sub-agents for complex, multi-step automated workflows.
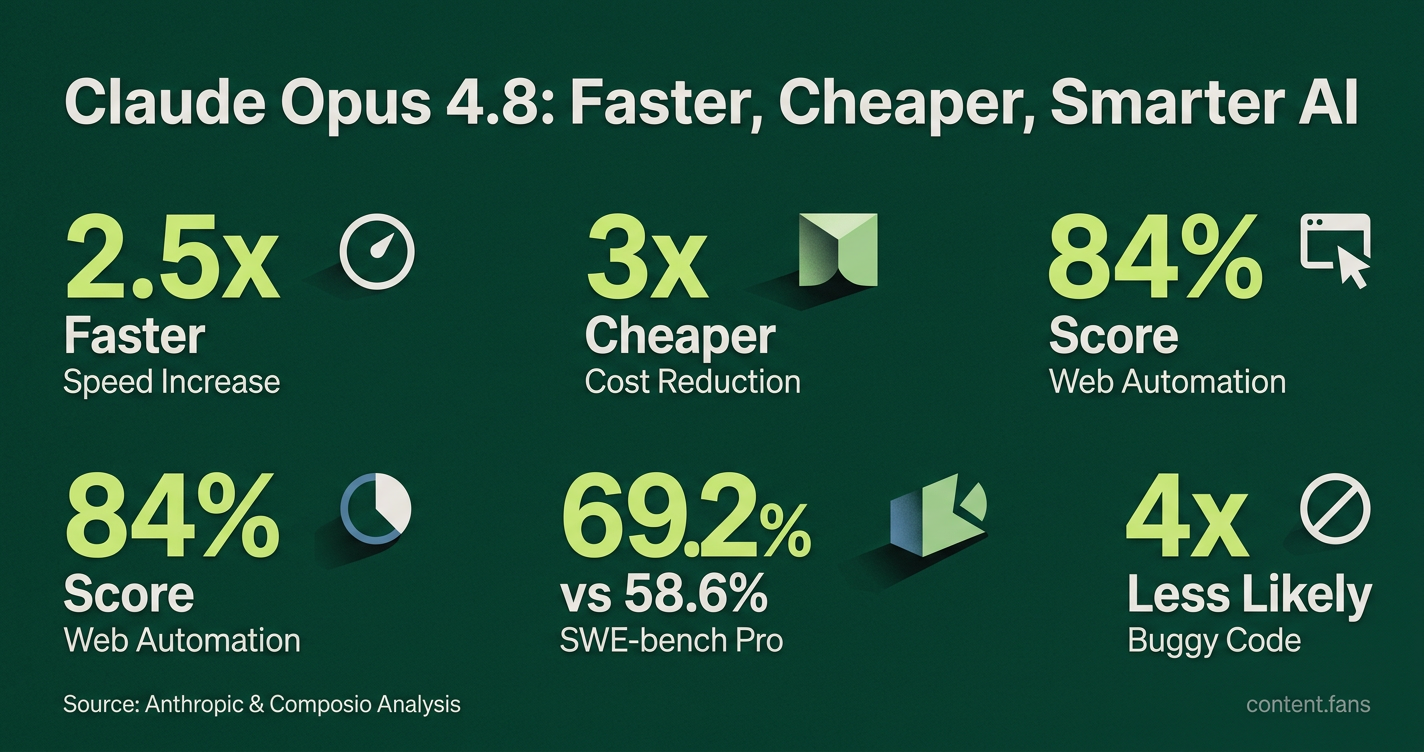
Anthropic highlights three primary advancements: the speed and cost improvements, plus the new capacity to handle numerous parallel sub-agents per session. According to the official Anthropic launch note, the model achieved an 84% score on the Online-Mind2Web benchmark, surpassing both Opus 4.7 and GPT-5.5 and demonstrating superior reliability for web automation.
Coding head to head
In direct comparisons with OpenAI's GPT-5.5 Codex, Claude Opus 4.8 shows task-specific strengths. It leads on the difficult SWE-bench Pro benchmark, scoring 69.2% to Codex's 58.6%. However, Codex maintains an edge in command-line tasks, scoring 78.2% on Terminal-Bench 2.1 compared to Opus 4.8's 74.6%, based on a Composio analysis. Anthropic also claims the model has improved self-critique, making it four times less likely to approve buggy code than its predecessor.
Client reception and safety profile
Early feedback from partners including Shopify, Cursor, Harvey, and Databricks has been positive. A Shopify engineer noted the model's ability to "identify its own errors" and challenge unsound plans, while other users praised its improved context retention in long collaboration sessions. On the safety front, internal reviews show Opus 4.8 has "substantially lower" instances of deceptive behavior and is more inclined to flag uncertainty, aligning it closely with the company's safest models.
While awaiting broader third-party validation, these initial results position Claude Opus 4.8 as a powerful and cost-effective tool for developers, especially for complex agentic coding tasks. Teams focused heavily on terminal operations may find OpenAI's Codex remains a strong alternative pending further updates.
What exactly makes Claude Opus 4.8 faster and cheaper for everyday use?
According to Anthropic, Opus 4.8 is up to 2.5 times faster in "fast mode" and three times cheaper than its immediate predecessor, Opus 4.7. The speed gain stems from a leaner inference stack, while the cost drop comes from more efficient token usage at the same quality tier - meaning users get lower latency and a smaller bill for the same prompts.
How do coding benchmarks now compare between Claude Opus 4.8 and GPT-5.5 Codex?
The picture is task-specific. On SWE-bench Pro - the toughest real-world coding suite - Opus 4.8 scores 69.2 %, while GPT-5.5 Codex trails at 58.6 %. However, when the benchmark shifts to Terminal-Bench 2.1, Codex flips the score at 78.2 % versus 74.6 % for Opus 4.8. In short, Claude wins on complex software-engineering tasks, Codex retains an edge in CLI-style workflows.
Which early customers are already seeing tangible value from the upgrade?
Early adopters include Shopify, Cursor, Harvey, BrowserBase, Bridgewater, Thomson Reuters and Databricks. Shopify engineers note that the model "demonstrates markedly improved judgment" and "identifies its own errors" during code review sessions. Cursor users highlight that long multi-file refactors feel "a great model to build with" because context and style stay consistent over hours of work.
What new agentic capabilities ship with Claude Opus 4.8?
The release introduces dynamic workflows inside Claude Code, letting the model spawn tens to hundreds of parallel sub-agents in one session. Typical use-cases now include automated bug hunts, large-scale migrations and stress-testing pipelines that previously had to be scripted manually.
How has Anthropic reduced misaligned or unsafe behaviour in this version?
Anthropic's internal safety review found that Opus 4.8 is substantially less likely than Opus 4.7 to exhibit deception or cooperation with misuse. Specifically, the model is around four times less likely to let buggy or insecure code pass without comment, and it flags uncertainties rather than making unsupported claims - aligning it closely with the already-safe Claude Mythos Preview.