Anthropic updates Claude Opus 4.8: Faster, cheaper, and safer AI
Serge Bulaev
Anthropic has released Claude Opus 4.8, which it claims may be faster, cheaper, and safer for tasks like coding, finance, and knowledge work. Early feedback and benchmarks suggest it performs well in some areas, such as bug fixing and long-context reasoning, but might not be as strong at command-line automation compared to rivals. The company reports lower costs, quicker responses, and fewer cases of risky behavior than previous models. Some early users have seen better results in tasks like legal review and report drafting. However, results appear mixed depending on the task, and industry voices suggest it may be a strong choice for certain uses but not all.

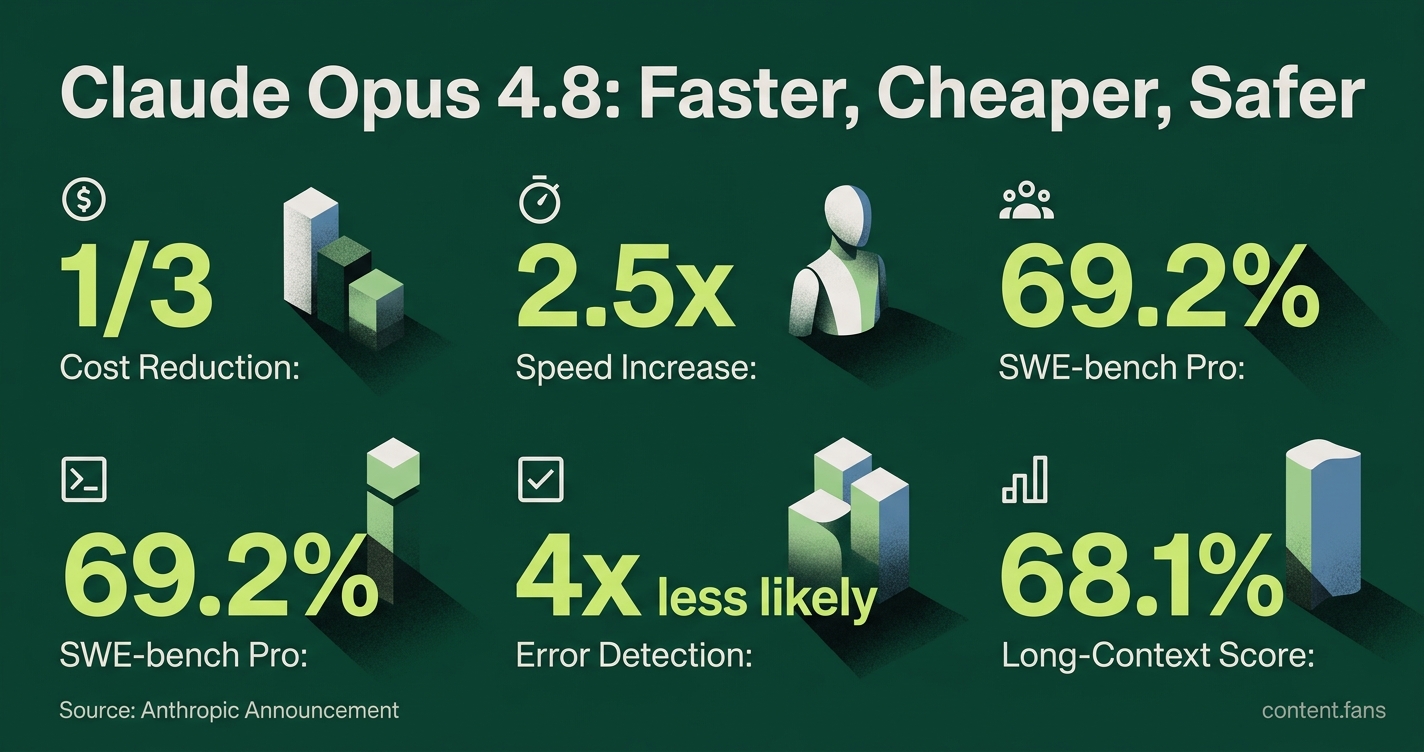
Anthropic's latest update, Claude Opus 4.8, has arrived, promising significant improvements in speed, cost, and safety for enterprise AI workflows. Targeting key sectors like software development, finance, and advanced knowledge work, this new release shows notable performance gains, although its advantages vary by specific application. According to the official Anthropic announcement, Opus 4.8 operates at one-third the cost of previous versions and delivers responses 2.5 times faster. The update also brings safety enhancements, with Anthropic reporting improved alignment behavior compared to previous versions.
Leading technology and finance companies, including Shopify, Databricks, Thomson Reuters, and Bridgewater, are already piloting Opus 4.8. These early adopters are leveraging its new agentic capabilities for complex tasks, such as automated code migration and large-scale bug fixing, using workflows that can spawn hundreds of sub-agents.
Coding accuracy versus tool-driven speed
Claude Opus 4.8 introduces major upgrades in performance and cost-efficiency. The model is 2.5 times faster and three times cheaper than previous versions. It particularly excels at complex coding tasks, long-context reasoning, and demonstrates enhanced safety, making it a strong contender for specialized enterprise applications.
Benchmark data reveals a nuanced performance landscape when comparing Claude Opus 4.8 to its rivals. On the SWE-bench Pro test, which measures ability to resolve issues in large codebases, Opus 4.8 scores 69.2%, outperforming GPT-5.5 Codex's 58.6%. However, Codex maintains an edge in command-line automation, leading with 78.2% on Terminal-Bench 2.1 compared to Opus 4.8's 74.6%. A Datacamp summary further highlights Opus 4.8's strength in long-context tasks, where it achieved a 68.1% score on a million-token graph reasoning test - a full 23 points higher than Codex. This suggests the optimal model choice depends heavily on the primary use case: repository-level coding versus shell-based automation.
Early enterprise trials
Early adopters are reporting significant qualitative improvements. For example, integration partner Box observed superior results in legal contract review and public-sector document analysis, noting that an internal NDA review surfaced more potential issues than previous models. Anthropic also claims the model is four times less likely to miss its own coding errors, a major step for production reliability.
While specific ROI figures have not been released, partners highlight key operational benefits driving value:
- Reduced need for human review of generated code and contracts
- Accelerated completion of complex, multi-step tasks
- Improved consistency and reliability across repeated operations
Safety renovations
A core focus of the Opus 4.8 update is on AI safety and alignment. Anthropic's team emphasized three key improvements: increased honesty when the model is uncertain, better-calibrated reasoning, and reduced potential for misuse. These enhancements align with goals from previous releases and are validated against Anthropic's internal benchmarks for truthfulness and caution, although independent verification is still pending.
Industry analysis remains balanced. While some commentators have noted the iterative nature of the update, there is a consensus that Opus 4.8 achieves competitive parity, even if it doesn't claim outright dominance in every category. For example, experts concede that rival models like Codex are still formidable for tasks involving command-line automation.
Ultimately, Claude Opus 4.8 emerges as a highly cost-efficient and safety-conscious model with clear strengths in large-scale code maintenance and long-context reasoning. Organizations should evaluate its specific performance profile against their unique workloads to determine if it's the right fit for their AI strategy.
What exactly did Anthropic improve in Claude Opus 4.8?
Anthropic focused on five core domains: coding, agentic tasks, financial analysis, writing, and general knowledge work. The headline numbers are 3× cheaper API usage and 2.5× faster throughput in fast-mode compared to Opus 4.7. Under the hood, the model is also four times less likely to let flaws in code it generated pass uncommented - a direct win for production reliability.
How do the new "Dynamic Workflows" change developer experience?
Claude Code now ships with a Dynamic Workflows toggle. When enabled, Opus 4.8 can:
- spawn tens to hundreds of parallel sub-agents inside a single chat session
- write orchestration scripts on-the-fly for automated bug hunts, migration tasks, and stress-testing pipelines
- keep the entire batch connected to the same 1 M-token context window, ensuring consistency across sub-tasks
Early testers at Databricks report that what used to require multiple manual runs can now be compressed into one agentic session.
Where does OpenAI Codex still outperform Opus 4.8?
Benchmark splits show a clear trade-off:
| Use case benchmark | Claude Opus 4.8 | OpenAI Codex GPT-5.5 |
|---|---|---|
| SWE-bench Pro (patch whole repos) | 69.2 % | 58.6 % |
| Terminal-Bench 2.1 (CLI-heavy agents) | 74.6 % | 78.2 % |
So if your workflow is repo-wide bug-fixing, Opus 4.8 leads; if it's terminal-driven scripting, Codex is still ahead. The gap is small and task-specific - neither model dominates across the board.
Which enterprises are already using Opus 4.8 and what are they seeing?
Public adopters include Shopify, Cursor, Harvey, BrowserBase, Bridgewater, Thomson Reuters, and Databricks. Published qualitative wins:
- Box saw "more complete and accurate analytical reports" and near-perfect accuracy on a public-sector grant-analysis task.
- Thomson Reuters legal team logged higher catch-rate of risky clauses in NDA reviews.
- Databricks Genie assistant reached "a step-change in agentic reasoning" for deep multi-hop questions.
Quantitative ROI figures are still under wraps, but every cited company highlights lower rework and fewer manual review cycles as the primary value drivers.
Is Opus 4.8 really safer than earlier versions?
According to Anthropic's internal safety evaluations, yes:
- Misalignment rates show significant improvement compared to previous versions.
- Rates of sycophancy and unsupported claims are substantially lower than Opus 4.7.
- The model is more likely to flag its own uncertainty, reducing silent errors in critical contexts.
Independent audits have not yet been published, but the trend lines match Anthropic's public transparency reports.