Snap's Bento ML platform processes 1 billion predictions per second
Serge Bulaev
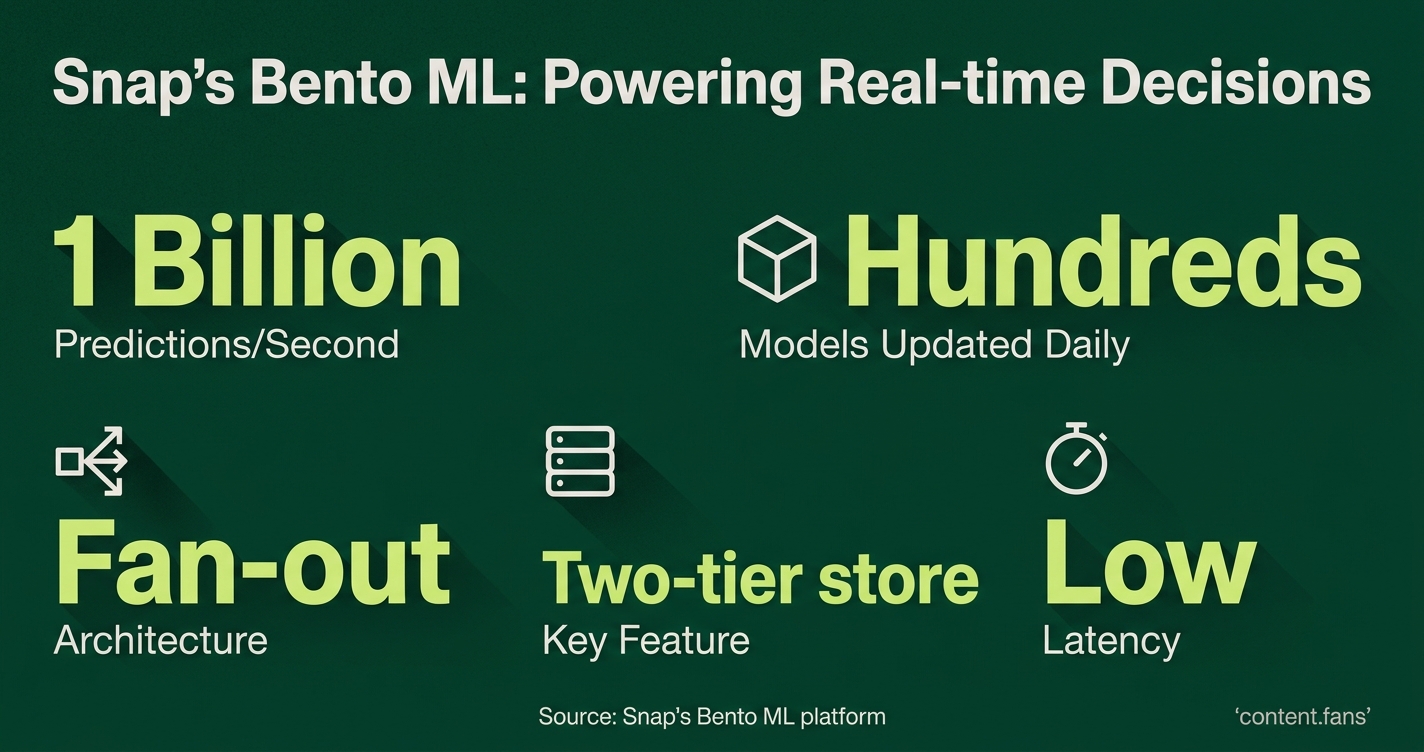
Snap's Bento ML platform may process up to 1 billion predictions every second. It is designed to support many Snapchat features, like Discover, Spotlight, ads, and AR lenses, by making fast ranking decisions. Snap suggests Bento helps keep delays low even with huge amounts of data and automates all model training jobs. The company shares that hundreds of models are updated daily, but some details about its technology and resources have not been disclosed. These facts suggest Bento is one of the more powerful machine learning systems used by large tech companies, but some claims may depend on data Snap has not made public.

Engineered to process up to 1 billion predictions per second, Snap's Bento ML platform powers the real-time ranking decisions for Snapchat's core products, including Discover, Spotlight, ads, and AR lenses. It is specifically designed for a "fan-out" architecture, where a single user action can trigger thousands of model evaluations.
Bento's architecture separates model training from model serving. This crucial division allows engineers to deploy updated models continuously without disrupting ongoing predictions, ensuring low latency even as the platform handles a significant volume of events daily.
How Bento Moves Data and Trains Models
Bento is a fully managed machine learning platform where every step, from feature generation to final deployment, is handled within a unified control plane. Snap describes Bento as supporting automated incremental retraining and a web UI for workflows, with engineers using a dedicated web interface for feature exploration, experimentation, and cost monitoring.
Bento is Snap's machine learning platform designed for high-volume, low-latency recommendations. It separates model training and serving, allowing for continuous updates without interrupting real-time predictions. The system uses a specialized two-tier feature store to prevent train-serve skew and maintain performance at scale across Snapchat's products.
To prevent train-serve skew - a common challenge in real-time ML systems - Bento writes features once and materializes them in two locations:
- A distributed key-value store for user-centric features.
- An instance-local store that co-locates document features with the inference engine.
This two-tier architecture, as detailed in Snap's Understanding Bento talk, is key to maintaining low latency at massive prediction volumes.
Scale numbers the company shares
Snap has disclosed several key statistics that illustrate the platform's large operational footprint:
- Hundreds of models are retrained or updated each day.
- A significant number of distinct models are live in production at any given moment.
- Feature and prediction volume have both grown substantially in recent years.
- Ranking model size has increased significantly since Bento's launch, while training data has grown substantially.
These figures come with the caveat that Snap has not released full architecture diagrams, specific hardware configurations (CPU/GPU/TPU mix), or resource costs.
Product surfaces that depend on Bento
Discover and Spotlight rely on Bento for fresh ranking signals. Snap has emphasized its development of "universal user understanding, graph understanding, and content understanding," which allows insights from one surface to be transferred to another. This architecture enables a unified feature graph to power multiple recommendation loops simultaneously.
The platform is used even more aggressively for ads. A real-time auction service calls Bento's prediction models during every ad impression, a process Snap considers core to delivering advertiser ROI. The company's marketing materials cite improvements in brand awareness and purchase intent for Snapchat campaigns, results likely influenced by Bento's precise targeting logic.
For augmented reality, Bento supports lens discovery and AR commerce. While Snap has not published lens-specific KPIs, its messaging confirms that AI is "at the heart" of its camera products. The platform's continuous retraining and high inference ceiling provide sufficient headroom for context-aware graphics without noticeable user delay.
Monitoring and governance layers
All telemetry from features and predictions is logged to Google Cloud Storage and can be queried via BigQuery. This allows engineers to inspect anomalies, model drift, and spending from the same dashboard used to launch jobs. Such integrated monitoring highlights Snap's focus on rapid experimentation and operational stability.
While Snap has shared significant details, information about its schema design, scheduler internals, hardware allocation rules, and proprietary inference engine remains undisclosed. Nevertheless, the published metrics position Bento among the highest-throughput in-house machine learning platforms in the consumer tech industry.
How does Bento reach high prediction volumes without melting Snap's data centers?
The trick is massive request fan-out: a single user swipe can explode into hundreds or thousands of (user, candidate) scoring calls inside Bento's serving tier.
To keep latency in check the platform keeps:
- 800 TB online feature store - split into a central key-value cluster for user signals and an instance-local store co-located with the inference engine for document features.
- 1 TB/s read throughput - so every micro-service can pull fresh features in milliseconds.
- CPU and GPU-specialized exports - of the same model, chosen automatically by the routing layer.
What parts of Snapchat actually run on Bento?
Snap's own lists are short and concrete:
- Discover & Spotlight - story, creator and video ranking
- Ad auction - real-time click-through-rate and conversion models
- Friend & Group suggestions - graph-based retrieval
- AR Lenses - lens recommendation and performance optimization
All surfaces share the same feature warehouse, experiment layer and deployment workflow, so a new signal built for ads can be reused by Spotlight the same day.
How fresh is the data that feeds those models?
Snap reports hundreds of billions of events daily and says Bento supports fully automated incremental retraining, with typical training-serving gaps measured in minutes:
- Incremental training is highly automated - new data lands, joins and gradients are computed with minimal manual intervention.
- Online pipelines replicate the offline transformations exactly to avoid train-serve skew - a requirement when you retrain frequently.
- Feature consistency checks block deployment if the online store drifts beyond a set threshold.
Does Bento only work for gigantic models?
No - Snap's public talk says they deliberately support "models of any size":
- Small logistic models still serve friend suggestions at the edge.
- Larger ranking networks now run for Discover after engineers scaled training data substantially without touching the serving contract.
- GPU clusters are optional; many models stay on CPU pools to save cost, because Bento exports hardware-specific binaries automatically.
How does Snap know Bento is moving business numbers?
Snap releases only directional results, but the figures are eye-catching:
- Ad auction throughput is now high enough to inject new signals hours after invention, shortening iteration from weeks to days.
- Model prediction volume and feature volume have grown substantially while latency stayed flat - a proxy for smoother user feeds.
- Marketing science claims Snapchat campaigns produce higher brand awareness lift versus competitors; Bento's rapid targeting refresh is cited internally as a key driver.
For engineers the clearest win is "significantly boosted ML engineering efficiency" - a polite way of saying teams ship more experiments per quarter without begging for extra GPUs.