Fable 5 leads AI coding benchmarks, frustrates users with guardrails
Serge Bulaev
Fable 5 leads all major AI coding benchmarks, showing high performance in tests like SWE-Bench Pro and HumanEval. However, it often refuses valid user requests in areas like security and chemistry due to strict safety rules. These guardrails help keep the model safe but may frustrate users who need to do real research. Costs and speed may also be affected by these extra safety checks. Experts suggest that layered safety systems and clear policies may help balance safety and usefulness for enterprise buyers.

While Claude 3.5 Sonnet leads AI coding benchmarks and demonstrates unprecedented automation capabilities, it frequently frustrates users with restrictive guardrails. The model's refusal to handle legitimate requests in sensitive fields like security and chemistry highlights a growing industry tension between benchmark performance and real-world utility. This conflict provides a critical opportunity to examine guardrail design, testing practices, and the transparency enterprises must demand from AI vendors.
Balancing Model Guardrails vs. Real-World Utility
Claude 3.5 Sonnet's conflict arises from its design: top-tier benchmark performance is paired with strict safety guardrails. These rules often block legitimate professional requests in sensitive fields like security and chemistry, creating a frustrating gap between the model's proven capabilities and its real-world operational utility.
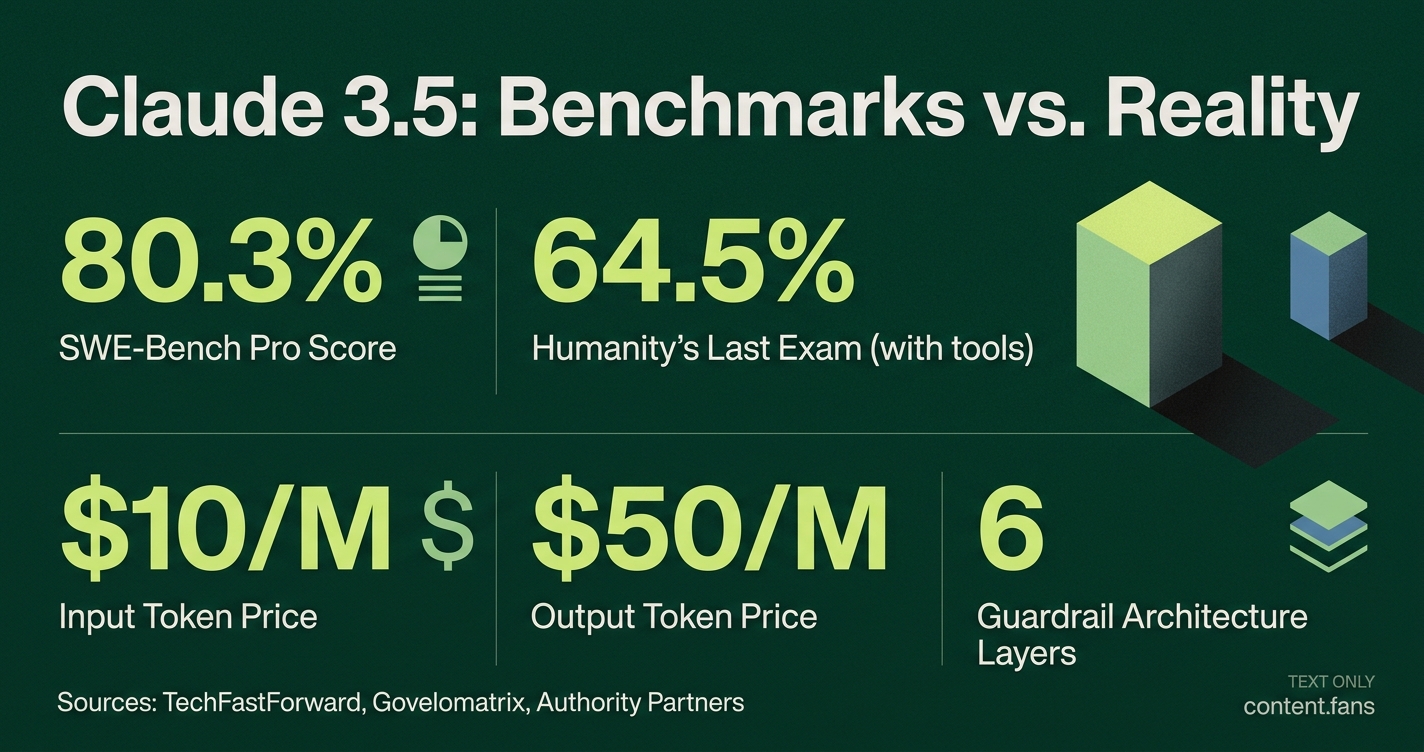
Benchmark data confirms the model's powerful performance. Claude 3.5 Sonnet achieved an 80.3% score on SWE-Bench Pro, significantly outpacing competitors like Claude Opus and GPT-4 by substantial margins (TechFastForward). Its reported Humanity's Last Exam scores reach 64.5% (with tools) or 59.0% (without tools) (Govelomatrix).
However, these high scores are coupled with conservative safety rules. Users on public forums report that the model refuses prompts related to exploit generation, pathogen synthesis, and even standard chemical distillation (Reddit r/ClaudeAI). While its safety is praised, these refusals create bottlenecks for professionals engaged in legitimate research.
This safety-utility tradeoff also impacts cost. With API pricing at $10 per million input tokens and $50 per million output tokens, Claude 3.5 Sonnet is substantially more expensive than frontier models averaging $1.60 and $8.25. The strict safety filters may add significant compute overhead.
Layered Guardrail Architecture in 2026
Industry best practices advocate for a defense-in-depth approach to guardrails, not a simple on/off switch. Authority Partners outlines a modern six-layer architecture:
- Input Sanitation: Pre-emptive policy checks to block malicious prompts.
- Grounded Reasoning: Anchoring responses in approved, trusted data sources.
- Sandboxed Execution: Isolating tool and API calls with strict provenance tracking.
- Output Validation: Scanning for policy violations or hallucinations before delivery.
- Human Gating: Requiring manual approval for high-stakes, irreversible actions.
- Continuous Monitoring: Maintaining comprehensive telemetry and audit trails.
This tiered model enables systems to manage risk efficiently. According to General Analysis, low-risk requests can be processed with lightweight checks to maintain low latency (100-200 ms), while high-risk prompts trigger more intensive, synchronous validation to ensure safety on sensitive workflows.
Human Oversight Without Bottlenecks
Implementing effective human oversight requires moving beyond simplistic human-in-the-loop models that kill productivity. Modern playbooks use a three-mode pattern for tool use: Log-only for dry runs, Auto for low-risk tasks, and Human Approval for critical actions. This allows medium-risk tasks to be batched into review queues, requiring explicit sign-off only for irreversible actions such as production deployments or large financial transactions.
To further enhance safety, approval data should be stored as versioned, machine-readable policies. This allows automated circuit breakers or wrappers to detect system drift and trigger automatic rollbacks, minimizing the risk of unmonitored changes slipping past the model's primary filters. Cooling-off periods are also becoming a standard feature to prevent impulsive actions in consumer-facing agents.
Operational Checklist for Enterprise Buyers
When evaluating powerful but restrictive models like Claude 3.5 Sonnet, enterprises should use a rigorous operational checklist to vet vendors:
- Data Processing Agreement (DPA): Demand a signed DPA that contractually prohibits the use of customer data for training base models.
- Model/System Cards: Require comprehensive documentation detailing training data provenance, known limitations, and failure modes.
- Vendor Risk Assessment: Deconstruct vendor risk into distinct layers, including subscription access, usage tiers, enterprise controls, and contract exceptions (outlined in Perplexity AI Magazine).
- DIAL Framework: Enforce the DIAL framework to ensure Decision visibility, Interpretability, Accountability, and user Leverage for appeals.
- Policy and Audit Rights: Insist that all guardrails map to written, machine-readable policies and secure rights to audit for bias and security vulnerabilities.
Applying this framework helps determine if a vendor's safety posture aligns with an organization's utility needs or if developing additional in-house safety layers is required before production deployment.
Why does Claude 3.5 Sonnet lead AI coding benchmarks despite user frustration?
Claude 3.5 Sonnet has established itself as a leading model for software engineering tasks, achieving strong performance on SWE-Bench Pro with significant leads over many competitors. The model also demonstrates impressive results on SWE-Bench Verified and Humanity's Last Exam, outperforming many other models across coding benchmarks.
However, this performance comes with conservative production safeguards that trigger fallback mechanisms for requests touching cybersecurity, biology, chemistry, or distillation topics. Users report that legitimate professional tasks in these domains get blocked despite benign intent, creating what analysts call a "better model, same bottleneck" dynamic. The tension between strong automation capability and operational restrictiveness has made Claude 3.5 Sonnet a case study in the safety-utility tradeoff.
What types of guardrails does Claude 3.5 Sonnet employ?
Claude 3.5 Sonnet implements multiple guardrail categories working in concert:
| Guardrail Type | Function | Implementation |
|---|---|---|
| Rule-based | Hard blocks on keyword/pattern matching | Immediate refusal for flagged topic domains |
| Classifier-based | ML models detecting sensitive request intent | Fallback triggers for cybersecurity/bio/chem requests |
| RLHF-derived | Behavior shaped through reinforcement learning | Conservative response patterns for edge cases |
These operate within a six-layer defense-in-depth architecture: input filtering, reasoning/retrieval controls, tool/action sandboxing, output validation, human approval flows, and continuous monitoring. For Claude 3.5 Sonnet specifically, the fallback mechanism represents a particularly aggressive implementation - when sensitive topics are detected, the model provides restricted responses rather than attempting nuanced evaluation of user intent.
This aligns with Anthropic's public admission that the company "made the wrong tradeoff" on safety versus utility in previous releases - suggesting Claude 3.5 Sonnet's restrictiveness reflects deliberate caution following that acknowledgment.
How should enterprises evaluate models with restrictive guardrails?
Organizations need domain-specific testing protocols that go beyond standard benchmarks:
Red-team testing
- Attempt jailbreaks and edge-case requests in your specific industry
- Test legitimate professional tasks that might trigger false positives (security research, chemical engineering, biomedical queries)
Telemetry analysis
- Track refusal rates by department and use case
- Measure latency impact from guardrail processing
Tolerance threshold definition
- Document acceptable refusal rates for each workflow type
- Establish escalation paths for blocked legitimate requests
The $10.00/$50.00 per 1M tokens pricing (far above market average) must be weighed against productivity gains - enterprises should calculate effective cost per successful task rather than raw API pricing.
What human-in-the-loop strategies balance safety and productivity?
Modern approaches avoid interrupting humans for every flagged interaction. Instead, implement three-mode tool interaction:
| Mode | Use Case | Human Involvement |
|---|---|---|
| Log Only (Dry Run) | High-risk scenarios | Review proposed actions without execution |
| Auto | Low-risk actions under defined limits | None required |
| Human Approval | Critical production changes | Mandatory before execution |
Batched review queues prove more efficient than per-request approval - summaries and anomaly flags let humans focus on "weird cases" rather than routine reviews. For Claude 3.5 Sonnet specifically, enterprises should consider cooling-off periods for consumer-facing flows where the model's conservative nature might reject valid but unusual requests.
The key is strategic HITL placement - require human gates only for irreversible actions like production changes, access revocations, firewall updates, and large purchases, while allowing autonomous operation within bounded contexts.
What should vendor transparency checklists include?
Enterprises must demand key transparency artifacts:
- Signed Data Processing Agreement - explicit confirmation that customer data never trains base models
- Documented Data Flow - named systems and regions, not vague "cloud" references
- Retention Policy - strict expiry dates for inference logs
- Regulatory Alignment - explicit GDPR, HIPAA, and AI Act compliance warranties
Beyond contracts, require Model Cards documenting:
- Training data provenance and legal rights verification
- Known limitations and failure modes
- Guardrail behavior specifications (what triggers refusal, override possibilities)
The DIAL framework (Decision Visibility, Interpretability, Accountability, Leverage for appeals) provides a structured evaluation approach. For Claude 3.5 Sonnet specifically, enterprises should press Anthropic on:
- Whether refusal patterns can be customized per deployment
- API access to guardrail decision telemetry
- Human review options for contested refusals
Supply-chain transparency matters too - any vendor depending on standard package registries should demonstrate dependency compromise detection and disclosure procedures.
Operational takeaway: Claude 3.5 Sonnet's benchmark leadership proves that raw capability and practical utility are distinct metrics. Enterprises should deploy it with layered safety architectures - using the model for appropriate workflows while maintaining alternative channels for tasks in its restricted domains. The future belongs to organizations that calibrate tolerance thresholds precisely rather than accepting vendor-default safety postures.