Every unveils 8 levels of AI adoption for teams
Serge Bulaev
Every has described eight levels of AI adoption for teams, starting from a simple chatbot and going up to an orchestrator that manages several sub-agents. The guide may help teams decide how much autonomy is right for their workflow and gives steps, prompts, and trust signals for each level. Reviews suggest the main benefit is that it gives teams a clear language to talk about AI use and risk. The eight levels focus on single tasks or small teams, which appears different from other models that look at the whole company. Observers think this ladder could make it easier for teams to move from testing AI tools to using them in regular work.

Every has introduced a framework outlining levels of AI adoption for teams, a guide designed to help organizations progress from simple chatbot experiments to more autonomous systems. Published by its consulting team, the practical guide maps AI usage progression, offering clear checkpoints for each stage (Every). This model emphasizes that AI autonomy is a flexible dial, not a status symbol; the appropriate level is determined by a workflow's tolerance for error and need for oversight. It provides a common language for teams to assess risk and decide when to scale their AI initiatives.
Understanding the Levels of AI Adoption
The levels of AI adoption represent a spectrum of increasing autonomy. The ladder progresses from basic chatbot interactions and copilot assistance with high human involvement, through mid-tier stages with greater automation, to highly autonomous systems that can coordinate multiple tasks.
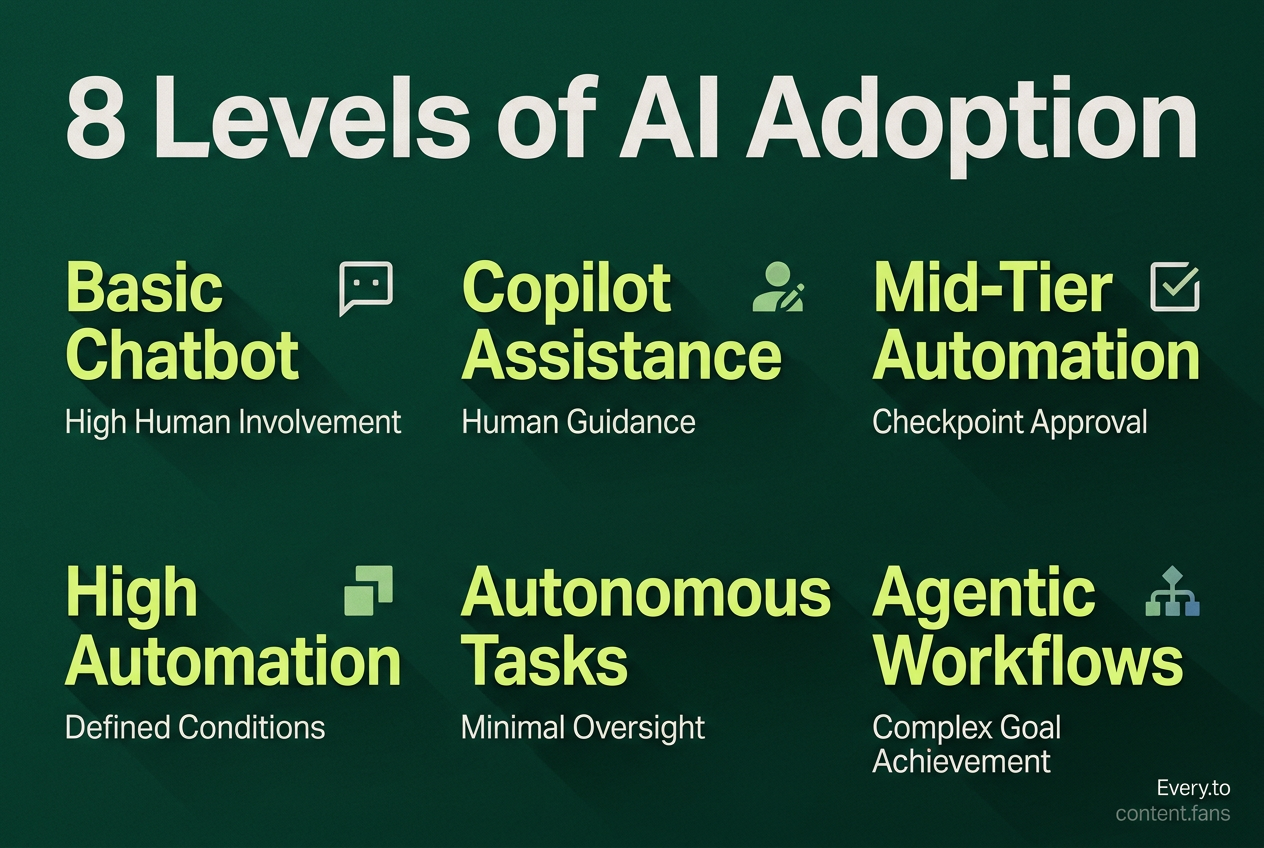
The framework outlines a clear progression in AI independence, moving from simple interactions to more complex autonomous operations. According to industry reports, organizations typically begin with basic AI assistance and gradually progress toward systems that can handle entire workflows with minimal human oversight.
The progression generally follows patterns where AI systems initially require constant human guidance, then move to checkpoint-based approval systems, and eventually reach stages where they can complete tasks end-to-end with human review after completion. Level 4 refers to high automation where the system can perform the driving task within defined operating conditions, often without human intervention in those conditions.
The source material describes a progression toward full workflows and autonomous task execution, with systems eventually capable of running multiple tasks or parallel agent sessions. The sources support autonomous or unsupervised task execution patterns as organizations advance their AI maturity. At the highest levels, the provided sources discuss agentic workflows and autonomy progression for complex goal achievement.
To help teams validate each stage, the guide includes sample prompts for testing AI capabilities and guardrails. For instance, a mid-level test might involve instructing an agent to draft and queue an email for approval before sending.
Key Adoption Signals: Trust, Cost, and Observability
According to early adopters, the framework's primary benefit is providing a clear, shared vocabulary for discussing AI implementation and risk. It helps teams distinguish between simple AI interaction and true task delegation. Advancement up the ladder is tied to three critical signals:
- Trust: Confidence in the AI's output is high enough for the given task.
- Cost of Error: The potential impact of a mistake is low and manageable.
- Observability: The team has tools to monitor AI actions and correct errors effectively.
The guide advises teams to delay advancing to a new level if any of these signals are weak. This structured vocabulary is reportedly being adopted in engineering and product meetings, allowing managers to track AI maturity with consistent, measurable checkpoints instead of abstract goals.
Team Workflow vs. Enterprise Readiness: Two Different Models
Every's framework is distinct from broader enterprise-level AI maturity models. While models like the one from SEI and Accenture evaluate an entire organization's readiness across dimensions like governance and data infrastructure (Morningstar release), Every's ladder focuses specifically on task-level autonomy for individuals or small teams.
Essentially, the two approaches answer different questions. Every's model asks, "How autonomous is the AI performing this specific task?" In contrast, enterprise models ask, "How prepared is our entire organization to deploy and scale AI?"
Industry analysts view Every's ladder as a crucial tool for bridging the gap between simple AI pilots and sophisticated, production-ready systems. By providing a language for controlled, incremental autonomy, it helps teams integrate AI into their regular workflows more smoothly.
What exactly are the levels of AI adoption laid out in Every's framework?
The ladder starts with basic chatbot interactions and progresses through various stages including copilot assistance, agent-based systems, and high-automation modes. Each stage increases the degree of autonomy the AI enjoys and lowers the amount of human oversight required.
How do I know when my team is ready to climb to the next level?
Every's guide gives concrete signals:
- Trust in the model's output is high enough that mistakes will not hurt critical outcomes
- Cost of error is low or can be contained with monitoring
- Observability tools are in place so you can catch and roll back bad decisions
If any of these three is missing, stay on the current level and tighten feedback loops before moving up.
Higher levels sound better - should we always aim for the highest level?
No. The framework explicitly warns that higher is not automatically better. A mid-level automated system that writes and deploys code nightly may deliver more value than a high-level orchestrator if your governance, compliance and rollback policies are not ready. Match the level to risk appetite and operational maturity, not bragging rights.
Are there real prompts I can use to test each level in practice?
Yes. Every supplies sample prompts for various stages. For example:
- Copilot level: "Refactor this Python function and leave inline comments explaining why."
- Assistant level: "Every Friday at 5 PM, summarise my week's Slack threads and email them to the team lead."
If the AI can execute the prompt reliably three times in a row without human edits, you have met the exit criteria for that level.
Where can I find the full essay and self-assessment?
The complete article - including the diagnostic quiz to identify your current level - is available on Every's site.