Amazon Expands Trainium AI Chip Use, Challenges Nvidia on Cost
Serge Bulaev
Amazon, Google, and Meta are focusing less on launching big AI models and more on building special chips, better data systems, and ways to run AI on different devices. Amazon appears to be using its Trainium chips more, which may help with costs compared to Nvidia, especially for certain kinds of AI work. Microsoft seems to be making its data tools easier for businesses but may also make it harder for companies to switch away from Microsoft later. Reports suggest most revenue in the AI space is now going to just a couple of companies, like Anthropic and OpenAI, though the exact numbers may vary. This situation means businesses might have to consider hardware, data platforms, and costs together when choosing AI tools.

As Amazon expands its Trainium AI chip use, the battle for AI dominance is shifting from large models to the underlying infrastructure. This move directly challenges Nvidia on cost, as tech giants like Google and Meta also focus on custom silicon, data systems, and efficient on-device compute.
The strategic stakes lie in who secures the cheapest tokens, the cleanest data paths, and the most portable deployment footprint for enterprises.
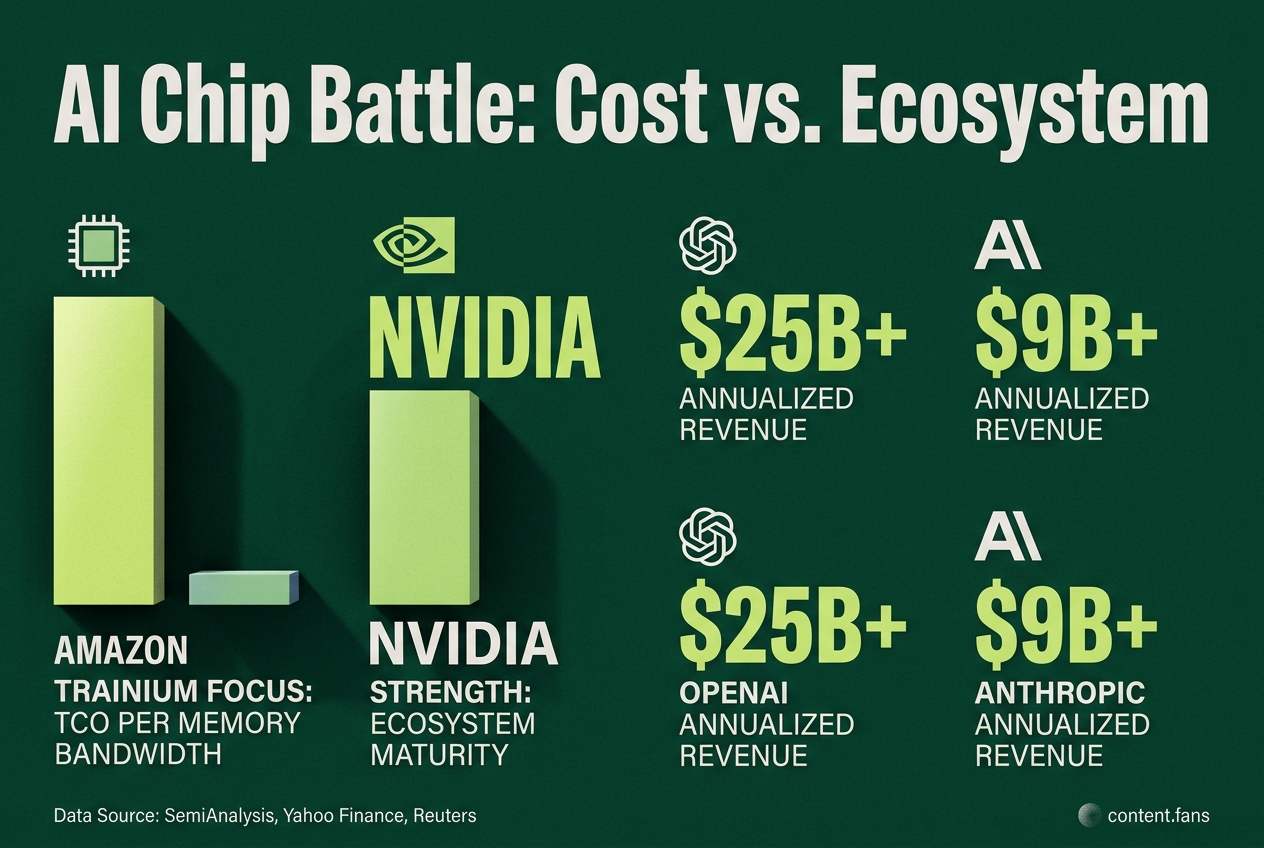
Custom Silicon Tilts the Cost Curve
Amazon is expanding its custom Trainium AI chip program to challenge Nvidia's dominance on cost and navigate GPU supply shortages. By optimizing for total cost of ownership (TCO) and memory bandwidth, AWS aims to provide a more economical alternative for large-scale AI training and inference workloads.
Amid persistent GPU shortages, Amazon is aggressively expanding its Trainium accelerator line. Reports from SemiAnalysis detail multi-gigawatt Trainium deployments within AWS, highlighting the chip's optimization for "best TCO per memory bandwidth" over traditional Nvidia cards. This rapid internal adoption is further confirmed by analyst summaries indicating significant Trainium2 deployments across AWS infrastructure (Yahoo Finance).
While public benchmarks are limited, anecdotal evidence suggests Trainium excels in large-batch training and cost-sensitive inference, crucial for conversational AI. Experts concede Nvidia maintains an edge in ecosystem maturity and low-latency performance, but Trainium's growing presence establishes it as a compelling alternative where cost-per-token is a higher priority than instantaneous response.
Data Control Through Microsoft Fabric
While Amazon focuses on hardware economics, Microsoft is solidifying its position by controlling the data layer. Industry reports suggest Microsoft is positioning Power BI and Fabric as a governed analytics pipeline for its Copilot and enterprise AI agents. Although this approach simplifies workflows for business teams, it risks creating significant vendor lock-in.
Analysts point to several potential lock-in areas:
- Semantic models embedded in Fabric datasets
- Copilot workflows that assume Microsoft identity controls
- Power Platform automations spanning Apps, BI, and Automate
While the immediate convenience is undeniable, migration costs escalate as more business logic and access rules become embedded in these proprietary formats.
Revenue Concentration Among Foundation-Model Startups
The battle for infrastructure control mirrors the concentration of revenue among top AI startups. As of early March 2026, Reuters reported OpenAI at over $25 billion in annualized revenue and Anthropic at approximately $9 billion in annualized revenue. Industry reports suggest Anthropic has achieved more efficient training costs relative to revenue generation compared to competitors.
These figures show a market consolidating around two primary vendors, even as tech giants like Apple, Meta, and Google develop their own on-device and multimodal hardware. For businesses, this underscores the need for a holistic AI strategy that evaluates hardware, data platforms, and vendor economics in tandem.
Why is Amazon expanding its Trainium AI chip program now?
AWS is scaling Trainium adoption because Nvidia GPUs remain scarce and expensive. Internal projects are deploying significant numbers of Trainium2 chips, and AWS is inviting outside teams to join the "Build on Trainium" program. Industry reports indicate some enterprises have chosen Trainium after benchmarking showed substantial cost savings versus Nvidia for large-scale workloads, giving developers a concrete incentive to consider the switch.
How does Trainium actually perform compared to Nvidia GPUs?
Head-to-head benchmarks still favor Nvidia on raw throughput and ecosystem maturity, but Trainium is winning on cost per token and memory-bandwidth efficiency. SemiAnalysis reports that AWS and Anthropic are planning multi-gigawatt clusters of Trainium specifically because "best TCO per memory bandwidth" matters more than peak TFLOPS when you are running large-scale, cost-sensitive inference for AI agents. For teams already inside the AWS stack, Trainium is becoming a lower-friction option once absolute latency is not the top priority.
What is Microsoft doing with Power BI to control enterprise data for AI agents?
Microsoft is turning Power BI into the semantic layer of its Fabric + Copilot + agentic AI stack. Instead of dashboards that only humans read, Power BI models now surface governed data and business logic directly to AI agents. If your agents learn to rely on these Microsoft-specific schemas, identity rules, and governance policies, the switching cost rises sharply - a textbook case of vendor lock-in through convenience.
How dominant are Anthropic and OpenAI in startup AI revenue?
Between them, Anthropic and OpenAI represent a significant portion of top AI-startup revenue. As of early March 2026, Reuters reported OpenAI at over $25 billion in annualized revenue and Anthropic at approximately $9 billion in annualized revenue. Anthropic's faster enterprise monetization and reportedly more efficient training spend per incremental dollar earned underscore why revenue efficiency, not just model quality, is becoming the decisive metric.
Which hardware strategies are Apple, Meta, and Google pursuing for on-device AI?
Each giant is doubling down on divergent silicon paths. Apple continues to integrate Neural Engine blocks into M-series and A-series chips to keep inference local on iPhone and Mac. Meta is pairing in-house MTIA chips with off-the-shelf GPUs to balance cost and supply for recommendation and generative workloads. Google is extending its Tensor Processing Units (TPU) roadmap with an eye on both cloud inference and future Pixel devices, ensuring vertical integration from data-center to pocket.